Análisis de las medidas del COVID-19
Contenidos:
- El problema
- Necesidad de Big Data
- Solución y trabajo existente relacionado
- Descripción de los datos
- Descripción técnica del modelo
- Explicación del código y como usarlo
- Evaluación del rendimiento
- Conclusiones
- Dificultades y optimizaciones
- Logros y próximos objetivos
1. Descripción del problema
Los casos de COVID-19 van en aumento y los expertos empiezan a hablar de que esto se podría convertir en una sexta ola. Es por esto que nuestro proyecto se centrará en el análisis de las distintas medidas sanitarias que han tomado los países (como por ejemplo el uso de mascarillas o el cierre de colegios), de tal manera que podamos ver su efectividad y prepararnos para próximas olas.
2. ¿Por qué necesitamos Big Data?
La necesidad de utilizar Big Data se debe al gran tamaño de los datos con los que vamos a trabajar y que además seguirá incrementándose a lo largo del tiempo puesto que los datos relativos a la pandemia se actualizan diariamente. Además de esto, tenemos una gran variedad de datos (salud, demografía, economía…).
3. Descripción de la solución
Para llegar a resolver el problema planteado realizaremos diversos graficos que muestren como ha afectado la pandemia (como por ejemplo las muertes o las hospitalizaciones) y como esto ha variado con las distintas medidas usadas. Al tener datos de todos los países del mundo, se tomarán varias muestras de paises de distintos continentes que nos ayudarán a sacar conclusiones como, por ejemplo, si ciertas medidas sanitarias han sido beneficiosas o no. Esto mostrará como algunas medidas han sido claves a la hora del control de la pandemia y nos ayudará a tener una idea de cuales serán las medidas que habrá que tener más en cuenta en una próxima ola. A la hora de realizar la mayoría de estos gráficos hemos tenido como base un dataset que mediante un índice marcaba la exigencia de ciertas medidas tal como se explica a continuación:
- Stringency_index: es un índice que marca la exigencia total de un país teniendo en cuenta la exigencia que ha tenido con cada una de las medidas. Este indice nos ayuda a tener una idea general de lo estricto que ha sido el país.Para más información acerca de como se calcula pinche aqui
- Otros indices: Cada una de las medidas tomadas tiene un indice propio que indicará lo estricto que ha sido un país con respecto a una medida específica. Este índice nos ayuda a estudiar medidas concretas y ver si han servido o no. Para más información acerca de estos índices pinche aqui
Limitaciones de la solución
Al tener un gran volumen de datos que hace referencia a todos los paises del mundo, nos hemos visto obligados a tomar una muestra de paises y sacar conclusiones a partir de estos, esto puede no ser representativo de la situación real. Es por esto, que para obtener una mejor solucion se debería hacer un estudio mucho más amplio, que abarque todos los países y todas las restricciones.
4. Descripción de los datos
Todos los datasets usados los hemos obtenido aqui
Datasets útiles que utilizamos en el proyecto
- Demographics
- Economy
- Epidemiology
- Health
- Hospitalizations
- Vaccinations
- Government Response
En la siguiente imagen vemos un ejemplo de Government Response (medidas tomadas por el gobierno):

5. Descripción técnica del modelo
Pyspark
En cuanto a sofware nuestra principal herramienta ha sido pyspark, con este hemos podido transformar los datasets mencionados anteriormente (en formato csv) en informacion útil para llegar a una solución al problema planteado (usando principalmente la funcion de filtrado y de union de diferentes datasets).
Pandas y MatplotLib
Estas dos librerias de python nos han permitido transformar la información que habiamos obtenido mediante pyspark en distintos graficos (como por ejemplo un histograma). De esta forma se puedan ver de manera mucho mas clara las soluciones obtenidas, además de poder compararlas entre sí (algo que es esencial en nuestro proyecto).
Google Cloud
Hemos usado GoogleCloud para ejecutar los scripts y poder comparar el tiempo que tardaba con lo que nos tardaba de forma local. De esta manera, aunque no estuvieramos trabajando con un volumen de datos tan grande se podría ver la mejora de rendimiento que nos proporciona esta herramienta.
Links
6. Explicación del codigo y como usarlo
Requisitos necesarios para ejecutar el software
Para ejecutar el software es necesario tener instalado python con las librerias de pandas y matplotlib, pyspark y un shell basado en unix.
Como ejecutarlo (de manera local)
En la consola se escribirá “spark-submit nombreDelFichero.py”, esto hará que spark ejecute el script y una vez vaya finalizando cada trabajo se nos abrirá otra pestaña que mostrará el gráfico obtenido (este grafico se puede descargar y una vez se haya hecho habrá que cerrar esta pestaña para que siga ejecutando el script).
Como ejecutarlo (en Google Cloud)
Se crea el cluster dataproc:
gcloud dataproc clusters create cluster-8322 --enable-component-gateway --region europe-west6 --zone europe-west6-c --master-machine-type n1-standard-4 --master-boot-disk-type pd-ssd --master-boot-disk-size 50 --num-workers 2 --worker-machine-type n1-standard-4 --worker-boot-disk-type pd-ssd --worker-boot-disk-size 50 --image-version 2.0-debian10 --project genial-tangent-326912
Se añaden los datasets y los scripts a un bucket para luego poder ejecutarlos desde el nodo maestro mediante spark-submit
BUCKET=gs://<BUCKET>
spark-submit $BUCKET/script.py $BUCKET/Datasets
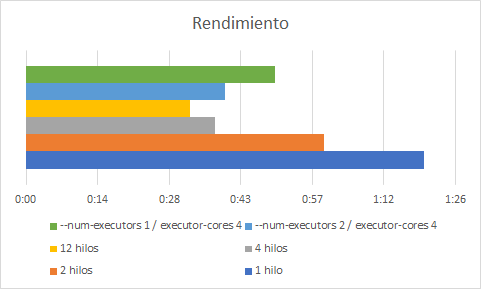
7. Evaluación del rendimiento
Hemos hecho varias pruebas en local y en el cloud con uno de los scripts que requiere mas procesado (muertes_cierre_Colegios.py):
8. Conclusión
Datos importantes a tener en cuenta
- Las conclusiones que se han obtenido son limitadas a los graficos obtenidos (que se limitan a una lista de varios paises y medidas) es por esto que no se deben tomar como conclusiones que se puedan aplicar realmente (pues para ello necesitariamos hacer un estudio mucho mas preciso de todos los paises y de todas las medidas)
- Tanto las muertes como las hospitalizaciones se muestran proporcionadas a la poblacion de cada pais, en cada grafico se muestra en la leyenda la proporcion utilizada (que ha variado entre los graficos para una mayor legibilidad)
- Aunque los indices de medidas específicas no son sobre 100 (suelen ser sobre 3 o sobre 4) se han reescalado para que sean sobre 100, nuevamente para una mayor legibilidad en los graficos
Las conclusiones que hemos obtenido varían dependiendo del script que se haya ejecutado por lo tanto se verá una conclusion por cada uno de los scripts y una conclusión que pueda englobar todos estos datos. En cada apartado se mostrará un ejemplo de los gráficos que se han obtenido con cada script, para verlos todos pinche aqui
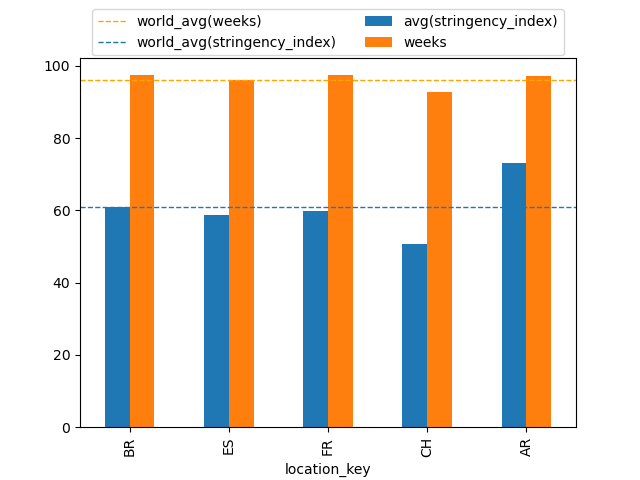
Conclusiones indicesPorPaises.py
Los paises que hemos seleccionado se encuentran cerca de la media mundial de exigencia de las medidas sanitarias (China está algo por debajo y Argentina un poco por encima) y de la media mundial del total de semanas con restricciones. Esto nos sirve para poder comparar paises con una exigencia parecida y ver que medidas ha tomado cada uno de los países.
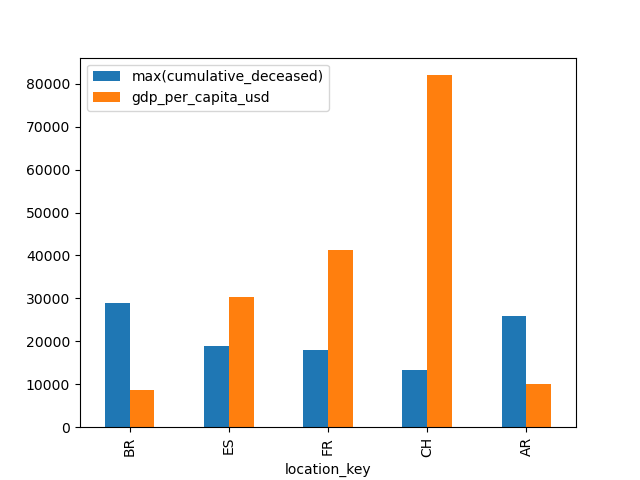
Conclusiones economia.py
En el grafico se puede ver como de los países seleccionados, los que tienen mayor pib per capita tienen un menor numero de fallecimientos por cada 10000000 habitantes. Por tanto hemos llegado a la conclusión que la riqueza del país es un factor importante a la hora de hacer frente a la pandemia del COVID-19. En la siguiente imagen se muestra el grafico de muertes respecto a la economia en una lista de paises:
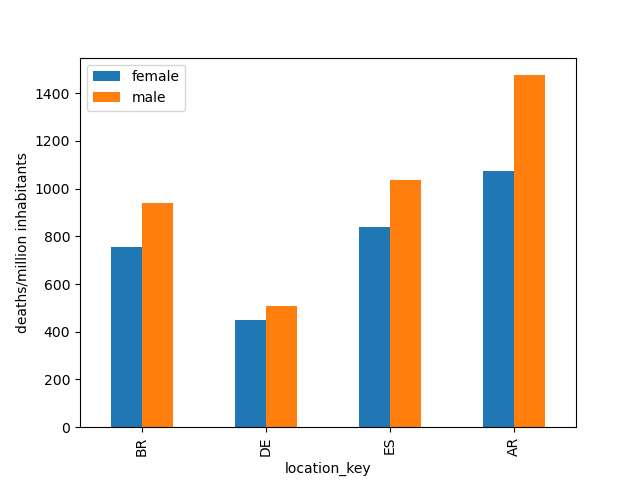
Conclusiones muertesPorSexo.py
Los datos obtenidos de los países estudiados muestran que la letalidad del coronavirus parece ser mayor entre los hombres que entre las mujeres por cada 1.000.000 habitantes. En la siguiente imagen se muestra el diagrama de barras que contrasta el número de defunciones de mujeres frente al número de defunciones de hombres en cada uno de los países seleccionados para el análisis:
Conclusiones muertesPorEdad.py
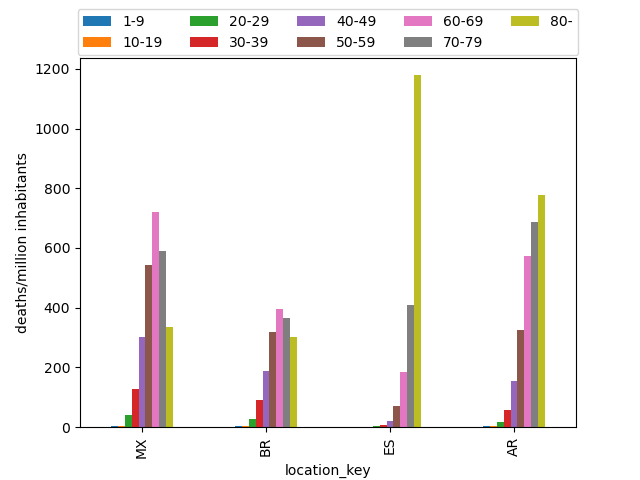
Los datos obtenidos de los países estudiados muestran que la gran mayoría de los fallecimientos se han producido en las personas de edad más avanzada, siendo la franja de edad de más riesgo la de los mayores de 80 años (donde se concentra el mayor número de muertes), seguida de la de entre los de 70 y 79 años. En la siguiente imagen se muestra el diagrama de barras que representa el número de defunciones por rango de edad por cada 1.000.000 habitantes en cada uno de los países seleccionados para el análisis:
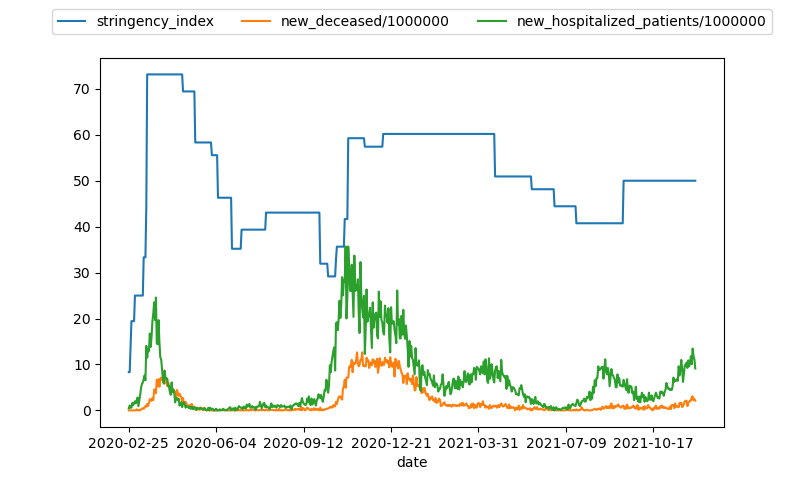
Conclusiones muertes_Restricciones.py
Este es un grafico general en el que se puede apreciar como el aumento en la exigencia de medidas sanitarias reduce los fallecidos y las hospitalizaciones. Sabiendo que las medidas sanitarias son algo necesario para la pandemia hemos analizado algunas medidas especificas para ver si estas son necesarias o no. En la siguiente imagen se muestra el grafico de restricciones en una lista de paises:
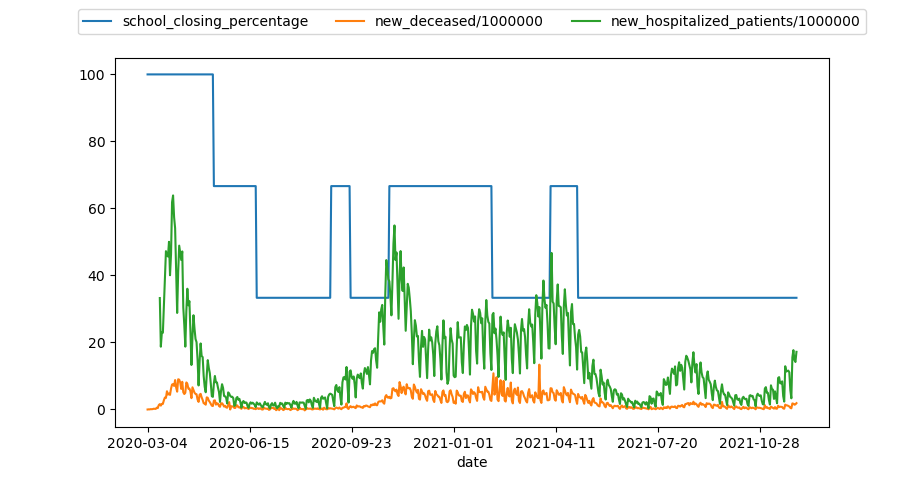
Conclusiones muertes_cierreColegios.py
En los paises que hemos estudiado siempre que se hace menos estricta la medida del cierre de colegios hay un pico de hospitalizaciones y muertes en las siguientes fechas, es por esto que podemos concluir que la medida del cierre de colegios en importante para el control de la pandemia. En la siguiente imagen vemos un ejemplo de estos gráficos en Argentina:
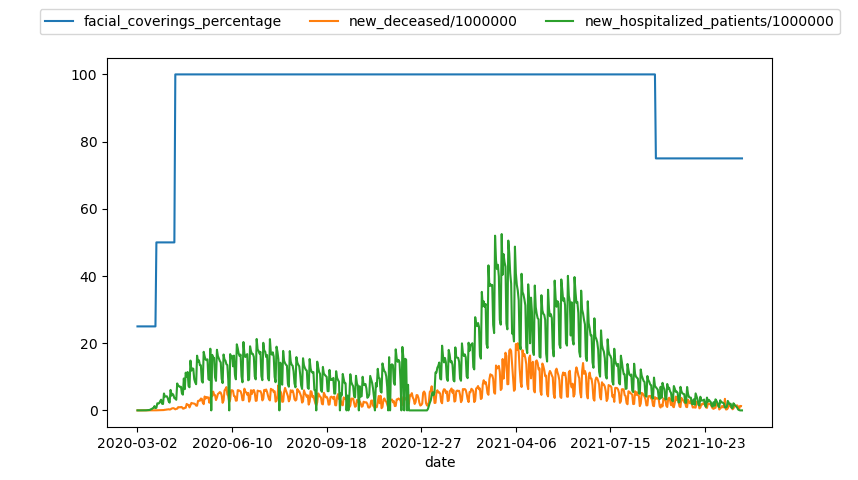
Conclusiones muertes_mascarillas.py
En todos los paises estudiados las mascarillas han estado vigentes en un nivel de exigencia de 3 o 4 la mayoria del tiempo, es por esto que con nuestro estudio no podemos sacar conclusiones acerca de su efectividad, más allá de la recomendacion de usarlas por parte de la OMS. En la siguiente imagen se muestra un grafico de ejemplo de las muertes y hospitalizaciones y la exigencia del uso de mascarillas en España:
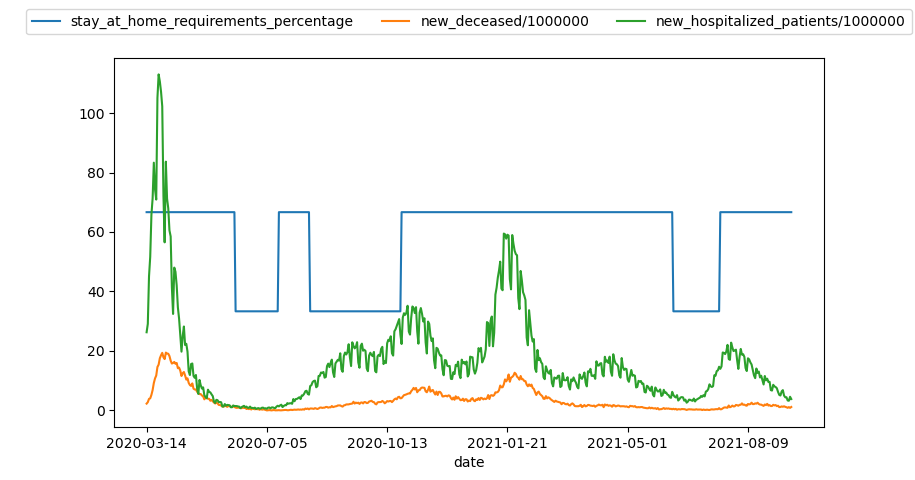
Conclusiones muertes_cuarentena.py
En los paises que hemos estudiado parece que cuando se sube la exigencia de la cuarentena disminuyen las muertes y hospitalizaciones, en la mayoria de paises han intentado ir disminuyendo esta medida debido a que en su mayor nivel de exigencia requiere parar un pais por completo, pero cada vez que aumentaban los casos volvian a tomar una mayor exigencia en esta medida. China, sin embargo, ha mantenido un nivel de exigencia 1. En la siguiente imagen se muestra un ejemplo de este grafico en Brasil:
Conclusiones mapa_stringency_index_mundial.py
Este mapa ilustra las restricciones de todos los paises con los ultimos datos disponibles sobre sus restricciones.

Conclusiones suma_casos_ultimos_dias.py
Comparación entre todos los países respecto a los casos confirmados en los ultimos 7 días.

Conclusiones casos_desde_inicio.py
Analisis de la curva de casos confirmados desde el inicio de la pandemia de varios paises.

9. Dificultades y optimizaciones
Dificultades: Tratar con una gran cantidad de Datasets, limitaciones de Google Cloud

Optimizaciones: Cachear los RDDs, seleccionar solo las columnas necesarias
10. Logros y próximos objetivos
Aumentar el estudio de las medidas específicas a todos los países para obtener resultados mas precisos.